Data Augmentation in Retinal Vessel Segmentation
Recently, we have been working on a research project where we study the impact of data augmentation in the performance of retinal vessel segmentation with Enes Sadi Uysal, Şafak Bilici, Selin Zaza and Yiğit Özgenç as a part of the inzva AI Projects program. The area of medical imaging has gained much attention in recent years and the retinal vessel segmentation is one of the fields that is widely studied. In this blog, we aim to explain what is retinal vessel segmentation and why data augmentation techniques impact the performance of the segmentation model?
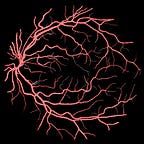
The input image is the output from the fundus camera. It is a camera that maybe all of us have sit in front of it in order to get the initial diagnosis of our eyes. It takes the photograph of our retina like below.

The input image of our study is in the shape of the image that shown in Figure 1. The purpose is to segment the vessel inside this image. This is quite important because these vessel are being used to diagnose several diseases like diabetes, migraine, cardiac diseases, cataract etc. The segmentation of thick vessels are not a big problem. However, when it comes to segment the thin vessels, the problem becomes quite challenging. It is challenging because:
- The number of annotated images are low, like in any other medical imaging tasks.
- Thin vessels are sometimes represented by only a single pixel.
- Location of the thin vessels may impact the deep learning model due to the pooling operations.
In order to address above issues, we need to have a strategy that makes our model to learn as much as it can from the available set of images. In our study, we use DRIVE dataset which is the most common benchmark in retinal vessel segmentation studies. It has 20 training and 20 testing images. Each image in the training set address to a different kind of retinal problem. Therefore, each image gives us a new information. An example from the DRIVE dataset is given below.

In the literature, there are architectures that are tailored for this specific problem. These architectures are mostly more advanced versions of the U-Net architecture. It takes more time to train (up-to 48 hours) these models compared to U-Net to get the extra gain in performance.
In our study, we took a different approach. The U-Net architecture is very successful architecture and it is a good fit for retinal vessel segmentation problem. Instead of making the model more complex, we relied on heavy data augmentation. In order to do it wisely, we needed to address the problems of fundoscopic images. These kind of images have specific noises due to the it’s sensors. The brightness of the input images are changing, some of them have very low brightness. In order to address these issues, we used the following data augmentation techniques.
- White Noise
- Elastic Deformations
- Rotation at different angles
- Shifting
- Cropping
- Zooming operations
Techniques and combinations of these techniques. The important part is to know why these techniques are working. White Noise and Elastic Deformations let the U-Net model to perform well when the input image is noisy. Rotated and shifted images let U-Net model to learn from the corners of the original input. Cropping and zooming operations makes thin vessels more accessible and model can learn more from these regions.
With the augmented images, the size of the training dataset increased to above 1000. The U-Net model is trained using these images and in Figure 3 an example from the model prediction is given along with the ground-truth.

Our model achieved 0.9855 Area Under the Curve (AUC) and 0.9712 accuracy score. It outperforms most of the models that has more complex architectures in the literature. Our model also outperforms other data augmentation based studies in the literature. Codes and implementation details are available at https://github.com/onurboyar/Retinal-Vessel-Segmentation.